
行动又名 AI 算法工程师,以前两年我最大的困扰是:思跑个 200 亿参数的模子,要么蹲云表 API 的配额,要么攒钱买一堆破钞级显卡堆工作器 —— 前者数据隐痛没保险,后者占所在不说声息还狠吵。 不外技嘉 AI TOP ATOM的出现,让我意志到:桌面级 AI 超等联想机,真的能治理咱们这些开发者的痛点。
从云表到腹地:AI 大模子的 “下千里” 趋势
近几年 AI 发展的要津词,除了 “大模子” 即是 “腹地化”。GPT-4、Claude 3 这类千亿级模子诚然纷乱,但云表调用不仅本钱高(按token计费),还面对数据泄漏风险 —— 比如你用公司里面数据微调模子,总弗成把敏锐数据传到第三方工作器吧?

“腹地部署大模子” 成为了刚需。不别传统有策动基本齐是粗重的工作器(占半个机房)+破钞级显卡(内存不够跑大模子)。而技嘉AI TOP ATOM的出现,将数据中心级的算力,压缩到1个高50.5mm宽150mm深150mm的迷你机箱里,放在办公桌就能用。
{jz:field.toptypename/}硬件:小机箱里的 “核弹级” 设立
AI TOP ATOM 不错径直放在流露器操纵完全不占所在。而其里面的设立实足会让全球吃惊:

● NVIDIA GB10 Grace Blackwell 超等芯片
NVIDIA最新的架构,集成了20核Arm CPU(10个Cortex-X925性能核+10个A725 能效核)和Blackwell GPU。
最要津的是,它能提供1 petaFLOP的FP4 AI算力—— 什么观念?至极于1000万亿次浮点运算/秒,满盈腹地跑200亿参数的大模子。

● 128GB 斡旋内存
真的统共东谈主齐知谈大模子最吃内存,AI TOP ATOM的128GB LPDDR5x 斡旋内存,带宽高达273GB/s,径直撑捏200B参数模子的腹地加载——不必再分块处理,推理速率快了至少3倍。

● ConnectX-7 智能网卡:
数据中心级的网卡,撑捏10GbE以太网和低蔓延通讯。
致使不错将两台 AI TOP ATOM 连起来径直算力翻倍,用来跑更大的模子(比如 405B 参数),对作念踱步式历练的开发者来说,爱游戏体育官网这比买一台大型工作器合算多了。
软件:开箱即用的 AI 开发环境
行动步调员设立环境一切责任的地基!不外设立环境真的是很繁琐很憋屈。
在这方面AI TOP ATOM预装了NVIDIA DGX OS,这是专为AI责任站联想的系统,内置了全套NVIDIA AI软件堆栈:CUDA、cuDNN、TensorRT、PyTorch、TensorFlow…… 致使连 ComfyUI、VS Code 齐预安设好了。

咫尺只需要把我方的数据集导入,用 TensorRT优化,不到2小时就能完成微调,再不必恭候云表工作器资源分派。而况数据全程在腹地,完全不必缅思泄漏。
愚弄场景:步调员的 “万能助手”
说真话AI TOP ATOM关于开发者来说,真的不错说是万能援手

● 原型开发:快速考据模子思法,用它跑图像 + 文本的推理,及时性比云表好太多。
● 腹地微调:用公司里面数据优化模子,比如历练一个能清楚家具文档的聊天机器东谈主,数据不必出公司内网。
● 角落部署:它的工致体积和低功耗,合适放在角落开拓操纵(比如工场的机器东谈主、市集的监控系统),径直在现场处理 AI 任务,蔓延真的为零。
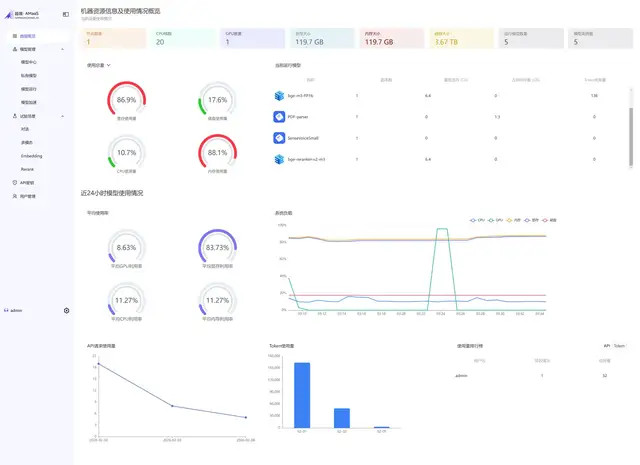
● 数据科学:跑特征工程、展望建模,腹地处理 TB 级数据,速率比平方台式机快 5 倍以上。
行业道理:AI 开发的 “难民化”
以前,大模子开发是大厂的专利 —— 需要百万级的工作器集群。AI TOP ATOM的出现,让个东谈主开发者和小团队也能领独特据中心级的算力。这就像当年PC升迁通常,缩短了 AI 开发的门槛,让更多东谈主能参与到大模子的立异中。
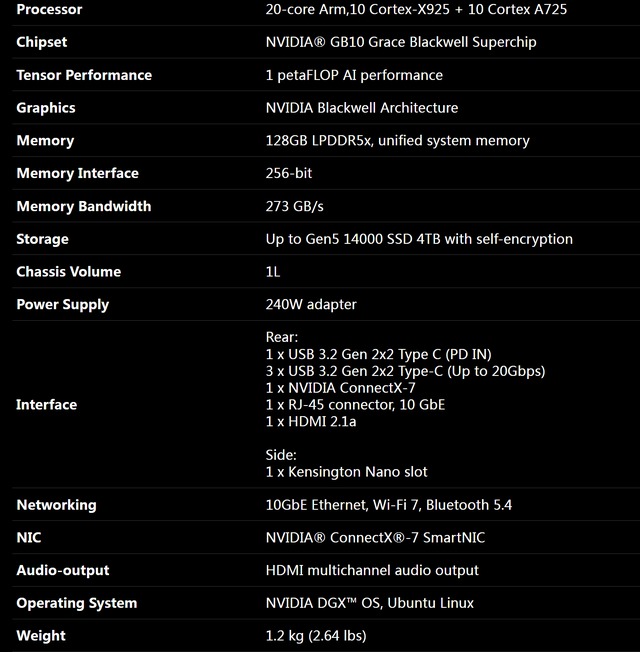
它的出现秀雅着一个趋势:AI 算力正在从云表走向桌面,从大厂走向平方开发者,桌面级AI成为施行!
 备案号:
备案号: